
AI画像生成ツールにテキストを入力して、ワクワクしながら結果を待つ。
そして、表示された画像を見て「……なんか違う」となった経験はありませんか?
- 構図がイメージと違う
- 雰囲気がなんか変
- 指が6本ある
こうしたガッカリの原因は、ほとんどの場合AIの性能ではなく、プロンプト(指示文)の書き方にあります。
Midjourney、DALL-E 3、Stable Diffusion、Fluxなど、最近のAI画像生成ツールはとんでもなく優秀です。
プロの写真やイラストと見分けがつかないレベルの画像を出せる。ただし、それは「適切な指示を出せたとき」の話です。
この記事では、AI画像生成の初心者でも今日から使えるプロンプトの書き方を、基本からしっかり解説していきます。
AIはどうやって画像を作っているのか(ざっくり理解)
プロンプトを上手く書くために、AIがどう動いているかをざっくり知っておくと役立ちます。
AI画像生成モデルは、大量の「画像+テキスト」のペアを学習しています。
「この言葉が入ったテキストにはこういう画像が対応していた」という統計パターンを膨大に覚えているわけです。
つまりAIは、あなたの言葉を「人間のように理解」しているのではなく、「この説明に最も合いそうな画像」を統計的に予測しています。
ここから導かれるポイントが3つ。
①具体的に書くほど精度が上がる。
「犬」より「ゴールデンレトリバーの子犬」、さらに「落ち葉の上で伏せているゴールデンレトリバーの子犬」のほうが、思い通りの画像に近づきます。
②AIは美術・写真の専門用語を知っている。
「レンブラント照明」「浅い被写界深度」「水彩画風」といった用語を使えば、細かいニュアンスをコントロールできます。
③プロンプトの前半が重視される。
ほとんどのモデルは、文の最初のほうに書かれた要素を優先します。一番大事な要素は冒頭に置きましょう。
プロンプトの5つの構成要素
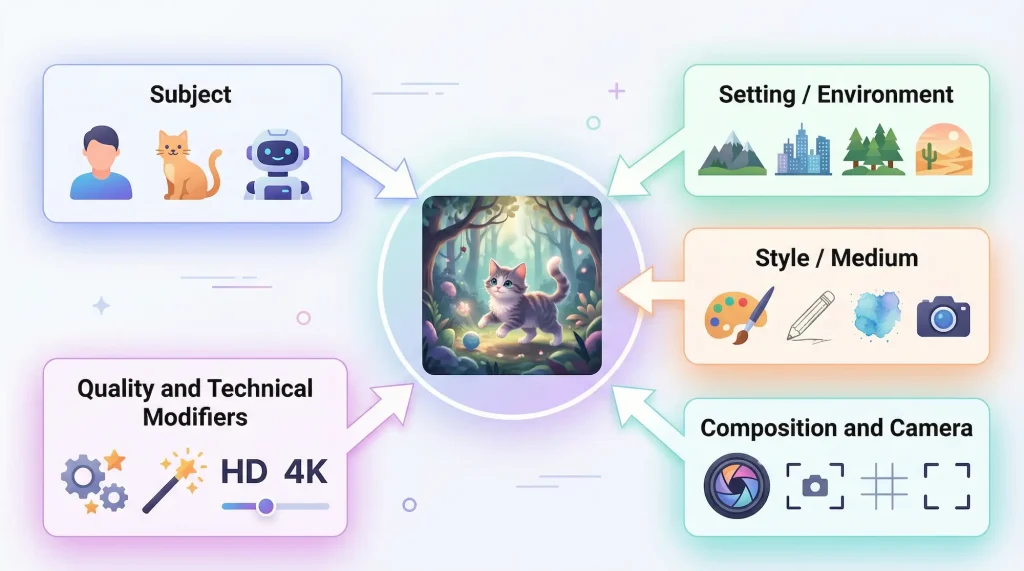
良いプロンプトには、以下の5つの要素が含まれています。
全部入れなくてもいいですが、この枠組みを頭に入れておくと指示がブレにくくなります。
①被写体(何が写っているか)
画像のメインとなるもの。ここが曖昧だと、すべてがぼやけます。
- いまいち:「女性」
- まあまあ:「ショートカットで丸眼鏡の若い女性」
- 良い:「30代の日本人女性、黒いピクシーカット、ネイビーのトレンチコートを着て、フィルムカメラを構えている」
詳しく書けば書くほど、AIの「想像の余地」が減り、あなたのイメージに近づきます。
②場所・環境(どこで)
同じ人物でも、場所が変われば画像の雰囲気はまったく違います。
- 「自動販売機が並ぶ夜の新宿の路地」
- 「朝靄の中の京都の竹林」
- 「天井まで窓がある白いアパートの一室」
場所の指定は、空気感や色味を大きく左右します。
③スタイル・媒体(どんなテイストで)
ここがプロンプトの中で最も強力なコントロールの1つです。
写真系: 「35mmフィルム写真」「ポートレート、浅い被写界深度」「ドローン空撮」「ストリートスナップ」
イラスト系: 「水彩画」「デジタルイラスト」「フラットベクターイラスト」「アイソメトリック3D」
雰囲気系: 「シネマティック」「ムーディー」「明るく爽やか」「ダークアカデミア風」
スタイルを指定するだけで、同じ被写体でもまったく違う画像が出てきます。
④構図・カメラ(どう撮るか)
写真用語が使えると、構図のコントロール精度が格段に上がります。
- ショットタイプ: クローズアップ、全身、俯瞰、ローアングル
- レンズ効果: ボケ、ティルトシフト、マクロ、魚眼
- ライティング: ゴールデンアワー、逆光、ネオン、ソフトディフューズ
⑤品質キーワード(仕上がりの底上げ)
出力のクオリティを上げるための定番フレーズがこちら。
- 「highly detailed」
- 「8K」
- 「professional photograph」
- 「sharp focus」
ただし、これらは1〜2個に絞るのがコツです。
全部盛りにしてもあまり効果は変わりません。
組み立て方のテンプレート
上の5要素を並べると、こんな形になります。
[被写体の詳細], [場所・環境], [スタイル],
[構図・ライティング], [品質キーワード]実例:
タトゥーの入った腕のバリスタがラテアートを注いでいる、
木の温もりがあるコーヒーショップ、大きな窓から朝日が差し込んでいる、
35mmフィルム写真、浅い被写界深度、
暖かいゴールデントーン、highly detailedこのプロンプトなら「誰が・何をして・どこで・どんな雰囲気で・どう撮ったか」が全部伝わります。
プラットフォーム別のコツ
各ツールにはクセがあります。同じプロンプトでも結果が違うので、使うツールに合わせた調整が大事です。
Midjourney
アーティスティックで美しい画像が得意。短めのプロンプトでも「いい感じ」に仕上げてくれる傾向があります。
覚えておきたいこと:
- 15〜60語くらいの短めプロンプトが効きやすい
--ar 16:9でアスペクト比指定(横長)、--ar 9:16で縦長--style rawでMidjourney独自の美化フィルターを弱められる--no text, watermarkでテキストや透かしを除外
Midjourneyプロンプト例:
夜の東京の小さな書店、暖かいランプの光、
木製の棚に本が溢れている、ガラスの扉の向こうに雨、
ジブリのような空気感 --ar 16:9 --v 6DALL-E 3
自然な文章をしっかり読み取ってくれるのが強み。複雑なシーンの指示に強く、画像内にテキストを入れるのも得意です。
覚えておきたいこと:
- 会話するように自然な文で書くとよく伝わる
- 「猫は左、犬は右」のような配置指定にも対応
- 不要なものは明示的に伝える(「文字は入れない」など)
DALL-E 3プロンプト例:
モダンなホームオフィスのフラットイラスト。
木のデスクにある大きなモニターにコードが映っている。
白猫がデスクの上で「Debug Mode」と書かれたマグカップの隣で眠っている。
左側の窓からやわらかい朝の光。
ミニマルですっきりしたスタイル、パステルカラー。Stable Diffusion
技術的なコントロールが最も細かくできるツール。括弧やウェイト指定など、独自の構文があります。
覚えておきたいこと:
- 括弧で強調:
(sharp focus:1.3)のように倍率を指定可能 - ネガティブプロンプトがとても重要(不要な要素を列挙)
- 品質トークン「masterpiece, best quality」が効果的
Stable Diffusionプロンプト例:
(masterpiece, best quality:1.2), 図書館で読書する女性の
ポートレート, ステンドグラス越しのvolumetric lighting,
(bokeh:1.1), 暖かいアンバートーン, photorealistic, 8K
Negative: lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, worst quality, blurryFlux
Black Forest Labs製の新しいモデル。
フォトリアルな画像が得意で、画像内テキストの精度も高いく、自然な文章で書けば素直に従ってくれます。
Stable Diffusionほど「おまじない」的なキーワードは必要ありません。
もう一歩踏み込むテクニック
基本を押さえたら、次のテクニックで仕上がりをさらに上げられます。
ネガティブプロンプト
「こうしてほしい」だけでなく「こうしないでほしい」も伝えましょう。
特にStable Diffusionでは必須級。
よく使うネガティブワード:
- 品質系: blurry, low quality, pixelated, artifacts
- 人体系: extra fingers, deformed hands, bad anatomy(AIあるある回避)
- 不要物系: text, watermark, signature, frame
スタイルの掛け合わせ
2つのスタイルを混ぜると、面白い画像が生まれることがあります。
- 「浮世絵風の現代東京の風景」
- 「アールヌーヴォー × サイバーパンク」
- 「水彩画タッチのSFイラスト」
カメラとレンズのシミュレーション
カメラ名やフィルム名を入れると、特定のルックが再現できます。
- 「Hasselblad, Kodak Portra 400」→ 温かみのあるフィルム調
- 「Fujifilm X-T5, 23mm f/1.4」→ クリーンでシャープな日常感
- 「Sony A7III, 85mm f/1.8」→ 美しいボケのポートレート
ライティングの指定
照明の種類を指定するだけで、画像の雰囲気がガラリと変わります。
- ゴールデンアワー — 夕方の温かい光。ポートレートや風景に。
- ブルーアワー — 日没直後の青い光。幻想的。
- レンブラント照明 — 顔の片側に三角形の光。ドラマチックな肖像。
- リムライト — 背後からの光で輪郭を際立たせる。
- ネオン — カラフルで都会的。サイバーパンク感。
やりがちなミス
「美しい風景」で止まる。
どんな風景?どこの?何時頃?天気は?季節は?AIは指定しなかった部分をランダムに埋めるので、具体性がないと毎回違う結果になります。
矛盾した指示。
「暗くて明るい」「霧がかかっていてクリアな」などは、AIが困ります。一貫したムードを決めましょう。
詰め込みすぎ。
キーワード100個より、核心を突いた30語のほうが良い結果が出ることも多いです。
アスペクト比を考えない。
デフォルトの正方形がベストとは限りません。ポートレートなら2:3や9:16、風景なら16:9のほうが自然に仕上がります。
1回で完璧を求める。
最初のプロンプトで完璧な画像が出ることはまずありません。結果を見て→微調整して→再生成、のサイクルを回すのが普通です。
自分なりのワークフローを作ろう
毎回ゼロからプロンプトを考えるのは非効率なため、自分なりの「型」を作っておくと、安定した結果が出やすくなります。
- まずゴールを言語化する。 この画像を写真や絵にするなら、何がどう見えるか?頭の中のイメージをことばにする。
- コアプロンプトを書く。 被写体 + 場所 + スタイル。まずはこの3つだけ。
- ディテールを足す。 構図、ライティング、雰囲気、色味。
- プラットフォーム固有の設定を追加。 アスペクト比、品質トークン、ネガティブプロンプト。
- 生成→評価→修正。 何が良くて何がダメかを言語化し、プロンプトに反映。
- 繰り返す。 満足いくまで5を回す。
最初は手間に感じますが、慣れると2〜3回の生成で狙い通りの画像が出せるようになります。
まとめ
AI画像生成はガチャではなくスキルです。
「指が7本ある」「なんか違う」を繰り返している人と、コンスタントに良い画像を出せる人の違いは、AIの使い方ではなくプロンプトの書き方にあります。
まずは5つの構成要素(被写体・場所・スタイル・構図・品質)を意識するところから始めてみてください。
それだけで結果は確実に変わります。
ツールの性能はすでに十分すぎるほど高いので、あとは「どう伝えるか」だけをマスターしましょう。